Алгоритмы сортировки
Пусть есть последовательность a0, a1... an и функция сравнения, которая на любых двух элементах последовательности принимает одно из трех значений: меньше, больше или равно. Задача сортировки состоит в перестановке членов последовательности таким образом, чтобы выполнялось условие: ai <= ai+1, для всех i от 0 до n.
Параметры, по которым производится оценка алгоритмов:
Время сортировки - основной параметр, характеризующий быстродействие алгоритма.
Память - ряд алгоритмов требует выделения дополнительной памяти под временное хранение данных. При оценке используемой памяти не будет учитываться место, которое занимает исходный массив и независящие от входной последовательности затраты, например, на хранение кода программы.
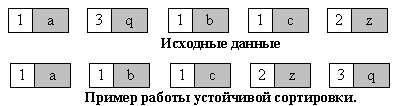
Устойчивость - устойчивая сортировка не меняет взаимного расположения равных элементов. Такое свойство может быть очень полезным, если они состоят из нескольких полей, как на рис. 1, а сортировка происходит по одному из них, например, по x.
Взаимное расположение равных элементов с ключом 1 и дополнительными полями "a", "b", "c" осталось прежним: элемент с полем "a", затем - с "b", затем - с "c".
Взаимное расположение равных элементов с ключом 1 и дополнительными полями "a", "b", "c" изменилось.
Естественность поведения - эффективность метода при обработке уже отсортированных, или частично отсортированных данных. Алгоритм ведет себя естественно, если учитывает эту характеристику входной последовательности и работает лучше.
Данный класс алгоритмов делится на два основных подкласса:
Внутренняя сортировка оперирует с массивами, целиком помещающимися в оперативной памяти с произвольным доступом к любой ячейке. Данные обычно сортируются на том же месте, без дополнительных затрат.
Внешняя сортировка оперирует с запоминающими устройствами большого объема, но с доступом не произвольным, а последовательным (сортировка файлов), т.е в данный момент мы 'видим' только один элемент, а затраты на перемотку по сравнению с памятью неоправданно велики . Это приводит к специальным методам сортировки, обычно использующим дополнительное дисковое пространство.
Быстрая сортировка (англ. quicksort), часто называемая qsort по имени реализации в стандартной библиотеке языка Си — широко известный алгоритм сортировки, разработанный английским информатиком Чарльзом Хоаром в 1960 году. Один из быстрых известных универсальных алгоритмов сортировки массивов (в среднем O(n log n) обменов при упорядочении n элементов), хотя и имеющий ряд недостатков.
1. выбрать элемент, называемый опорным.
2. сравнить все остальные элементы с опорным, на основании сравнения разбить множество на три — «меньшие опорного», «равные» и «большие», расположить их в порядке меньшие-равные-большие.
3. повторить рекурсивно для «меньших» и «больших».
Алгоритм
Быстрая сортировка использует стратегию «разделяй и властвуй». Шаги алгоритма таковы:
1. Выбираем в массиве некоторый элемент, который будем называть опорным элементом. С точки зрения корректности алгоритма выбор опорного элемента безразличен. С точки зрения повышения эффективности алгоритма выбираться должна медиана, но без дополнительных сведений о сортируемых данных её обычно невозможно получить. Известные стратегии: выбирать постоянно один и тот же элемент, например, средний или последний по положению; выбирать элемент со случайно выбранным индексом.
2. Операция разделения массива: реорганизуем массив таким образом, чтобы все элементы, меньшие или равные опорному элементу, оказались слева от него, а все элементы, большие опорного — справа от него. Обычный алгоритм операции:
2.1. Два индекса — l и r, приравниваются к минимальному и максимальному индексу разделяемого массива соответственно.
2.2. Вычисляется индекс опорного элемента m.
2.3. Индекс l последовательно увеличивается до m до тех пор, пока l-й элемент не превысит опорный.
2.4. Индекс r последовательно уменьшается до m до тех пор, пока r-й элемент не окажется меньше либо равен опорному.
2.5. Если r = l — найдена середина массива — операция разделения закончена, оба индекса указывают на опорный элемент.
2.6. Если l < r — найденную пару элементов нужно обменять местами и продолжить операцию разделения с тех значений l и r, которые были достигнуты. Следует учесть, что если какая-либо граница (l или r) дошла до опорного элемента, то при обмене значение m изменяется на r-й или l-й элемент соответственно.
3. Рекурсивно упорядочиваем подмассивы, лежащие слева и справа от опорного элемента.
4. Базой рекурсии являются наборы, состоящие из одного или двух элементов. Первый возвращается в исходном виде, во втором, при необходимости, сортировка сводится к перестановке двух элементов. Все такие отрезки уже упорядочены в процессе разделения.
Поскольку в каждой итерации (на каждом следующем уровне рекурсии) длина обрабатываемого отрезка массива уменьшается, по меньшей мере, на единицу, терминальная ветвь рекурсии будет достигнута всегда и обработка гарантированно завершится.
Интересно, что Хоар разработал этот метод применительно к машинному переводу: дело в том, что в то время словарь хранился на магнитной ленте, и если упорядочить все слова в тексте, их переводы можно получить за один прогон ленты.
Оценка эффективности
QuickSort является существенно улучшенным вариантом алгоритма сортировки с помощью прямого обмена (его варианты известны как «Пузырьковая сортировка» и «Шейкерная сортировка»), известного, в том числе, своей низкой эффективностью. Принципиальное отличие состоит в том, что после каждого прохода элементы делятся на две независимые группы. Любопытный факт: улучшение самого неэффективного прямого метода сортировки дало в результате эффективный улучшенный метод.
Лучший случай. Для этого алгоритма самый лучший случай — если в каждой итерации каждый из подмассивов делился бы на два равных по величине массива. В результате количество сравнений, делаемых быстрой сортировкой, было бы равно значению рекурсивного выражения CN = 2CN/2+N, что в явном выражении дает примерно N lg N сравнений. Это дало бы наименьшее время сортировки.
Среднее. Даёт в среднем O(n lg n) обменов при упорядочении n элементов. В реальности именно такая ситуация обычно имеет место при случайном порядке элементов и выборе опорного элемента из середины массива либо случайно.
На практике (в случае, когда обмены являются более затратной операцией, чем сравнения) быстрая сортировка значительно быстрее, чем другие алгоритмы с оценкой O(n lg n), по причине того, что внутренний цикл алгоритма может быть эффективно реализован почти на любой архитектуре. 2CN/2 покрывает расходы по сортировке двух полученных подмассивов; N — это стоимость обработки каждого элемента, используя один или другой указатель. Известно также, что примерное значение этого выражения равно CN = N lg N.
Худший случай. Худшим случаем, очевидно, будет такой, при котором на каждом этапе массив будет разделяться на вырожденный подмассив из одного опорного элемента и на подмассив из всех остальных элементов. Такое может произойти, если в качестве опорного на каждом этапе будет выбран элемент либо наименьший, либо наибольший из всех обрабатываемых.
Худший случай даёт O(n²) обменов. Но количество обменов и, соответственно, время работы — это не самый большой его недостаток. Хуже то, что в таком случае глубина рекурсии при выполнении алгоритма достигнет n, что будет означать n-кратное сохранение адреса возврата и локальных переменных процедуры разделения массивов. Для больших значений n худший случай может привести к исчерпанию памяти во время работы алгоритма. Впрочем, на большинстве реальных данных можно найти решения, которые минимизируют вероятность того, что понадобится квадратичное время.
Улучшения
При выборе опорного элемента из данного диапазона случайным образом худший случай становится очень маловероятным и ожидаемое время выполнения алгоритма сортировки — O(n lg n).
Выбирать опорным элементом средний из трех (первого, среднего и последнего элементов). Такой выбор также направлен против худшего случая.
Во избежание достижения опасной глубины рекурсии в худшем случае (или при приближении к нему) возможна модификация алгоритма, устраняющая одну ветвь рекурсии: вместо того, чтобы после разделения массива вызывать рекурсивно процедуру разделения для обоих найденных подмассивов, рекурсивный вызов делается только для меньшего подмассива, а больший обрабатывается в цикле в пределах этого же вызова процедуры. С точки зрения эффективности в среднем случае разницы практически нет: накладные расходы на дополнительный рекурсивный вызов и на организацию сравнения длин подмассивов и цикла — примерно одного порядка. Зато глубина рекурсии ни при каких обстоятельствах не превысит log2n, а в худшем случае вырожденного разделения она вообще будет не более 2 — вся обработка пройдёт в цикле первого уровня рекурсии.
Разбивать массив не на две, а на три части (см. Dual Pivot Quicksort).
Достоинства и недостатки
Достоинства:
Один из самых быстродействующих (на практике) из алгоритмов внутренней сортировки общего назначения.
Прост в реализации.
Требует лишь O(lgn) дополнительной памяти для своей работы. (Не улучшенный рекурсивный алгоритм в худшем случае O(n) памяти)
Хорошо сочетается с механизмами кэширования и виртуальной памяти.
Существует эффективная модификация (алгоритм Седжвика) для сортировки строк — сначала сравнение с опорным элементом только по нулевому символу строки, далее применение аналогичной сортировки для «большего» и «меньшего» массивов тоже по нулевому символу, и для «равного» массива по уже первому символу.
Недостатки:
Сильно деградирует по скорости (до Θ(n2)) при неудачных выборах опорных элементов, что может случиться при неудачных входных данных. Этого можно избежать, используя такие модификации алгоритма, как Introsort, или вероятностно, выбирая опорный элемент случайно, а не фиксированным образом.
Наивная реализация алгоритма может привести к ошибке переполнения стека, так как ей может потребоваться сделать O(n) вложенных рекурсивных вызовов. В улучшенных реализациях, в которых рекурсивный вызов происходит только для сортировки меньшей из двух частей массива, глубина рекурсии гарантированно не превысит O(lgn).
Неустойчив — если требуется устойчивость, приходится расширять ключ.
Поразрядная сортировка (Цифровая сортировка) — алгоритм сортировки за линейное время.
Алгоритм сортировки, числа сортируются по разрядам. Существует два варианта least significant digit (LSD) и most significant digit (MSD). При LSD сортировке, сначала сортируются младшие разряды, затем старшие. При MSD сортировке все наоборот. При LSD сортировке получается следующий порядок: короткие ключи идут раньше длинных, ключи одного размера сортируются по алфавиту, это совпадает с нормальным представлением чисел: 1, 2, 3, 4, 5, 6, 7, 8, 9, 10. При MSD сортировке получается алфавитный порядок, который подходит для сортировки строк. Например "b, c, d, e, f, g, h, i, j, ba" отсортируется как "b, ba, c, d, e, f, g, h, i, j". Если MSD применить к числам разной длины, то получим последовательность 1, 10, 2, 3, 4, 5, 6, 7, 8, 9.
При MSD сортировке последовательность сортируется по старшему значимому двоичному разряду так, чтобы все ключи начинающиеся с 0 оказались перед всеми ключами начинающимися с 1. Для этого необходимо найти крайний слева ключ Ki, начиющийся с 1, и крайний справа ключ Kj, начиющийся с 0. После чего Ki и Kj меняются местами, и процесс повторяется, пока не получится i > j. Пусть F0 — множество элементов начинающихся с 0, F1 — множество всех остальных элементов. Будем к F0 применять поразрядную сортировку (начав теперь со второго бита слева, а не со старшего) до тех пор, пока множество F0 полностью не рассортируется. Затем проделаем то же самое с F1. Применение для строк
Вместо сравнения N-й битовой позиции в слове сравнивается N-й байт строки.
Нулевой проход использует только нулевые символы в каждой строке и является корзинной сортировкой по нулевому символу. Эффективная реализация возможна при использовании массива ссылок на строки вместо самих строк, дополнительного массива «границ корзин», инициализируемого частотами встреч символов при первом проходе, они же число элементов в каждой «корзине». При следующем проходе заполняется массив ссылок.
N-й (для N > 0) проход выполняется последовательно над каждой корзиной, полученной на (N - 1)-м проходе, с делением её на «подкорзины». В этом проходе сравниваются N-ные символы каждой строки.
Операция завершается при N, равном максимальной длине строки, или же в ситуации, когда все «подкорзины» получили длину 1.
Сортировка подсчётом
ортировка подсчётом — алгоритм сортировки, в котором используется диапазон чисел сортируемого массива (списка) для подсчёта совпадающих элементов. Применение сортировки подсчётом целесообразно лишь тогда, когда сортируемые числа имеют (или их можно отобразить в) диапазон возможных значений, который достаточно мал по сравнению с сортируемым множеством, например, миллион натуральных чисел меньших 1000. Эффективность алгоритма падает, если при попадании нескольких различных элементов в одну ячейку, их надо дополнительно сортировать. Необходимость сортировки внутри ячеек лишает алгоритм смысла, так как каждый элемент придётся просматривать более одного раза.
Предположим, что входной массив состоит из n целых чисел в диапазоне от 0 до k − 1, где . Далее алгоритм будет обобщён для произвольного целочисленного диапазона. Существует несколько модификаций сортировки подсчётом, ниже рассмотрены три линейных и одна квадратичная, которая использует другой подход, но имеет то же название. КомпонентныйПаскаль
Простой алгоритм.
PROCEDURE CountingSort (VAR a: ARRAY OF INTEGER; min, max: INTEGER);
VAR
i, j, c: INTEGER;
b: POINTER TO ARRAY OF INTEGER;
BEGIN
ASSERT(min <= max);
NEW(b, max - min + 1);
FOR i := 0 TO LEN(a) - 1 DO INC(b[a[i] - min]) END;
i := 0;
FOR j := min TO max DO
c := b[j - min];
WHILE c > 0 DO
a[i] := j; INC(i); DEC(c)
END
END
END CountingSort;
Сортировкаслиянием
Сортировка слиянием (англ. merge sort) — алгоритм сортировки, который упорядочивает списки (или другие структуры данных, доступ к элементам которых можно получать только последовательно, например — потоки) в определённом порядке. Эта сортировка — хороший пример использования принципа «разделяй и властвуй». Сначала задача разбивается на несколько подзадач меньшего размера. Затем эти задачи решаются с помощью рекурсивного вызова или непосредственно, если их размер достаточно мал. Наконец, их решения комбинируются, и получается решение исходной задачи.
Для решения задачи сортировки эти три этапа выглядят так:
Сортируемый массив разбивается на две части примерно одинакового размера;
Каждая из получившихся частей сортируется отдельно, например — тем же самым алгоритмом;
Два упорядоченных массива половинного размера соединяются в один.
Рекурсивное разбиение задачи на меньшие происходит до тех пор, пока размер массива не достигнет единицы (любой массив длины 1 можно считать упорядоченным).
Нетривиальным этапом является соединение двух упорядоченных массивов в один. Основную идею слияния двух отсортированных массивов можно объяснить на следующем примере. Пусть мы имеем две стопки карт, лежащих рубашками вниз так, что в любой момент мы видим верхнюю карту в каждой из этих стопок. Пусть также, карты в каждой из этих стопок идут сверху вниз в неубывающем порядке. Как сделать из этих стопок одну? На каждом шаге мы берём меньшую из двух верхних карт и кладём её (рубашкой вверх) в результирующую стопку. Когда одна из оставшихся стопок становится пустой, мы добавляем все оставшиеся карты второй стопки к результирующей стопке.
Алгоритм был изобретён Джоном фон Нейманом в 1945 году.[1]
Время работы алгоритма порядка O(n * log n) при отсутствии деградации на неудачных случаях, которая есть больное место быстрой сортировки (тоже алгоритм порядка O(n * log n), но только для лучшего случая). Расход памяти выше, чем для быстрой сортировки, при намного более благоприятном паттерне выделения памяти — возможно выделение одного региона памяти с самого начала и отсутствие выделения при дальнейшем исполнении.
Популярная реализация требует однократно выделяемого временного буфера памяти, равного сортируемому массиву, и не имеет рекурсий. Шаги реализации:
над каждым отрезком входного массива InputArray[N * MIN_CHUNK_SIZE..(N + 1) * MIN_CHUNK_SIZE] выполняется какой-то вспомогательный алгоритм сортировки, например, сортировка Шелла или быстрая сортировка.
устанавливается ChunkSize = MIN_CHUNK_SIZE
сливаются два отрезка InputArray[N * ChunkSize..(N + 1) * ChunkSize] и InputArray[(N + 1) * ChunkSize..(N + 2) * ChunkSize] попеременным шаганием слева и справа (см. выше), результат помещается в OutputArray[N * ChunkSize..(N + 2) * ChunkSize], и так для всех N, пока не будет достигнут конец массива.
ChunkSize удваивается
если ChunkSize стал >= размера массива — то конец, результат в OutputArray, который (ввиду перестановок, описанных ниже) есть либо сортируемый массив, либо временный буфер, во втором случае он целиком копируется в сортируемый массив.
иначе меняются местами InputArray и OutputArray перестановкой указателей, и все повторяется с пункта 4.
Такая реализация также поддерживает размещение сортируемого массива и временного буфера в дисковых файлах, то есть пригодна для сортировки огромных объемов данных. Реализация ORDER BY в СУБД MySQL при отсутствии подходящего индекса устроена именно так (источник: filesort.cc в исходном коде MySQL).